
CAN ARTIFICIAL INTELLIGENCE BE CREATIVE?

Some scientists claim that the brain is essentially just a computer [i], so if people can be creative, so can machines. Perhaps artists will go the way of telephone switchboard operators. But others demur. Arthur I Miller’s book The Artist in the Machine: The World of AI-Powered Creativity surveys the ways in which machines are becoming involved in art, poetry, music, and thinking. Can their input be ‘creative’? In this paper, Udo Wuertz - Deputy Chief Data Officer, BLP Europe for Fujitsu, a Fujitsu Distinguished Engineer and a leading commentator on AI - responds to one of the key issues in Miller’s book. How, asks Wuertz, does an AI programme recognise and process information so that it can undertake such tasks as analysing and classifying pictures it is shown, and then generating further pictures of its own? Exactly what happens at the constituent detailed levels of data? How do those details build up to provide a fuller description? And how does the AI way of arriving at that point differ from human thought patterns? Those enquiries lead Wuertz to a conclusion which answers the fundamental question: is AI, operating in such a manner, able in principle to act creatively
— PAUL CAREY-KENT

PAPER: NEURAL NETWORKS AND THE DEEP DREAM
Everybody has some idea of what AI is or could be. Some of this is true, some is probably exaggerated, and some is clearly exaggerated. In fact, AI is ‘nothing more’ than mathematics. But isn't there more to it than that?
Well, to answer this question we need a basic framework of knowledge about artificial neural networks. These networks constitute the part of a computing system designed to simulate the way the human brain analyses and processes information: in other words, the part which represents the actual AI.
So the first question is, how do neural networks actually function? Let us take a simple example. Imagine, we have a camera and this camera takes a photo which is exactly 4 pixels (Figure 1). No colour, only black and white. Perhaps nobody would buy such a limited camera, but that is not the point.
Suppose we would like to be able to recognise patterns in these images. A horizontal line, for example. How do we do that? Well, the first step is to evaluate the input information, the pixels. So we have to determine attributes like position, colour, brightness etc. In AI, that's what neurons do. It sounds complicated but, in the end, neurons are simply software (functions).

Figure 1: A four-pixel camera
One must also keep in mind that the most-used programming language for AI applications is Python, which was written in the late 1980s. Thus about 30 years old. The first PC saw the light of day in 1984 and data was still stored on floppy disks. Just to put the topic of ‘artificial[P1] intelligence’ into the right context.
Back to our neurons. We have the pixels and we want to process them now. The first step will be to build an input layer, to assign the pixels to these neurons and assign their positions (Figure 2). In the next step we have to think about how to convert the brightness of the pixels into numbers. A neural network can only do numbers, nothing else. So we could envisage / create a kind of brightness table (Figure 3), and use it to generate the values. This is exactly what we do.
And now we can work with it and mathematically preserve the original information for the following layers, so to speak. Now that we have the pixel values, we can process them further in the next layer. It is important to know that every neuron, i.e. every piece of software that takes care of a pixel in our example, has a so-called receptive field. This field should simply give us an indication of what information the corresponding neuron is concerned with. So it's purely logical and I have illustrated it here to provide further clarification (Figure 4).

Figure 2: Brightness levels

Figure 3: Brightness Table
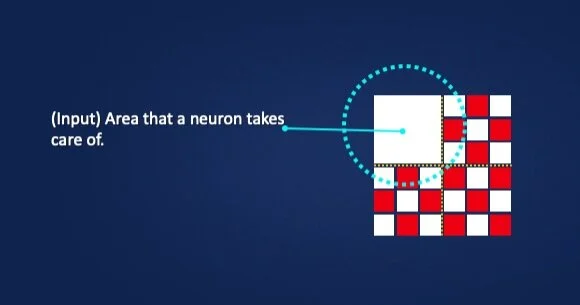
Figure 4: Neuron input
We now add more software layers, meaning: more neurons that are connected to the others (Figure 5). These connections are not just connections: later on we’ll assign them differing importance depending on which connection passes the information from the previous layer to the next layer. This is similar to real life: we often give information from superiors a higher priority than information we receive from our peers. And it is similar in AI. More on this later.
As a result, this information is increasingly combined, i.e. completed, from layer to layer. This procedure is repeated until we have taken all the information into account. Admittedly one can imagine this better if one looks at our small, and surely also strongly simplified, net in its entirety. The so-called receptive fields are shown here.
Suppose we take a horizontal line with the camera and want to have it analysed by our network. Since we only have distinct black and distinct white pixels here on the image, the values are simple: black = 1 and white = +1, which is easy and should help us to understand the processes better.
Important: Connections that we do not have to consider are not shown here, in order avoid making the picture too complex. In reality, all neurons of one layer are connected to the neurons of the layer before and after.

Figure 5: Layers of Neurons
In the first layer, this information is now combined into pixels of 2. So we combine the pixels top left / bottom left, top right / bottom right. But wait a minute, the pixel patterns look different now, don't they? That is correct: let me explain why (Figure 6).

Figure 6: Input layer to first layer
In the input layer, the upper neurons represent the two black pixels of our image, so their value is -1. The lower two represent the white pixels, so the value is +1. So far so good.
Thus we pass these values on to the neurons of the first layer. This layer combines them. By the way, the neurons in the first layer are so-called sum neurons. This means that they add together the values that they receive from the previous layer, i.e. the input layer. To ensure that these values do not become too large from layer to layer, mathematics comes into play. You see the Sigmoid symbol?
This means Hyperbolic Tangent or Sigmoid function. I don't want to bore you with mathematics, otherwise we could stop at this point because nobody would want to read on. I’d just say this much: the function makes sure that our values stay at -1 or +1. Practical, isn't it? This saves us computing time, because large numbers can consume a lot of computing power, and therefore training such neural networks can take an extremely long time.
But let's take a closer look at layer 1: the upper neurons are grey (Figure 7). Grey means: inactive. Here's what happened: the two upper neurons of layer one got values from the input layer. One black, -1, and one white, +1. The neurons added their values: (-1) + (+1), which is zero.

Figure 7: Inspecting the upper neurons of Layer 1
0 on the other hand means: nothing happens here anymore, end of work - time for the pub, so to speak.
However, the two lower neurons are active, why (Figure 8)? Now, you see the yellow lines? Those are the connecting lines between the layers. These indicate that they're negative. The white ones are positive, by the way. Now we'll ignore the values they represent to keep our little example simple. So just +/-.

Figure 8: Inspecting the lower neurons of Layer 1
So how do you know which connection is or must be positive or negative? The AI does this automatically, at first at random. The assignment of positive or negative numbers to a connection is called weighting. And all that the AI tries to find out is: which weighting (i.e. numbers) do I have to create, and how must I combine them with the values of neurons to get the desired result? But what is the desired result? Well, typically we train an AI with known data. For example, with images on which we mark the objects to be recognised. That's called ‘labelling’ in the technical jargon. The AI processes these images and tries to get a result with the numbers it generates, which is more or less the same as the label. If this works reasonably well, the AI can later examine unknown images and tell us what is to be seen there.
That's all. It's just mathematics. It can be more complex, but it's still mathematics. No intelligence, no emotions, no feelings. Numbers are numbers, and numbers have no intelligence or feelings. They represent values. Full stop. Still exciting, I hope. In fact, one of the main tasks of a Data Scientist is to process this data and to adjust the AI to get the best possible result. This is not easy and therefore takes a lot of time.
Back to our lower neurons of layer 1, so the upper one now gets a -1 from the input layer. The connecting line is positive. The AI multiplies the values and if you multiply a negative value by a positive value, the value remains negative. So when -1 occurs, we simply ignore the value of the weighting to keep the example clear.
The second value for the upper neuron is +1, but via a negative connection. Thus +1 multiplied by a negative weighting of the line and voila: now the neuron adds these values: (-1) + (-1) and gets -2. However, our little function ensures that we can always have -1 and +1 at most, so -2 becomes -1. And the lower neuron of layer 1 does the same. And these -1’s are passed on by the neurons to the next layer (Figure 9).

Figure 9: Tracing connections between layers
What can I say? Here's how it goes. The upper neurons are inactive (= 0), because the previous ones are too. So nothing happens here anymore.
The third neuron from above also becomes neutral. Why? We deliver from layer 1 a total of twice -1, but once with a negative weighting. And if you multiply a negative number (-1) with a negative weighting, it becomes +1. And (-1) + (+1) = 0, and thus inactive.
The lower neuron remains and when we look at the receptive field, we already see a line. The wrong way around but a line at least.
You see how the receptive fields change layer by layer? This gives us a very good impression of what information these neurons are now dealing with. We are getting closer and closer to recognising our pixel pattern. So, on to the net.
If the value is 0, nothing happens here either, so the upper six neurons are all inactive.
So we come to the ReLu with the last active neuron. First with -1, which becomes 0 and the ReLu inactive (second ReLu from below). So we already have seven inactive neurons in layer 3. Then the last neuron gets a -1 multiplied by a negative weighting. Fortunately. Because this turns into +1 and the ReLu likes that. So it passes on +1.
The neuron in the output layer is activated and shows: ‘We have detected a horizontal line!’
If you now feed such a net with thousands of these pictures (Figure 10), the AI collects the numbers in a kind of treasure box, also called a trained model. And, honestly: nobody really understands why these and those numbers were generated, that is currently the subject of research. Really! That's why the layers between input and output are called hidden layers. Because you can't see what exactly happens there.
If one now puts unknown images into such a trained net, then the AI can make a prediction based on the learned numbers, to indicate the probability with which it can conclude it is about a given pattern.

Figure 10: A ‘net’.
But how can an A.I. ‘dream’ now? The book ‘The Artist in the Machine’ refers to it, also under https://deepdreamgenerator.com/ you can see some very interesting and remarkable examples.
The question that arises is: how does it work? How can an AI ‘dream’?
Actually, it can't. An AI does not dream because it has neither the necessary consciousness nor any other ‘system’ similar to the human. An AI does not experience anything that it has to process ‘in its sleep’. In this respect, the term ‘dreaming’ is technologically misleading.
Also terms like ‘neurons’ should not hide the fact that these are not neurons in the human sense, i.e. ‘components’ of the brain. An artificial neuron is ultimately only software and mathematics.
Also, processors or GPUs are not built like brains. For example, they cannot adapt to new circumstances and rebuild themselves in the way a brain can. Ultimately, they are number crunchers which can perform extremely fast calculations and use software to recognise patterns in data, often better than a human could. And this recognition of patterns is what makes it so interesting.
Why do I say this so definitely? Because rationality is decisive in the technological sense. I am deeply convinced of this. When we exaggerate technology and attribute to it human-like capabilities that it does not possess, we are transfiguring the essential. I would even claim that, in such a state of exaggeration, progress is hardly possible - because in the end it is only real capabilities that can be further improved, and not hypothetical ones.
With this basic understanding, we can now turn to the question of how such images can arise.
If we look at the, admittedly highly simplified, example of the neural network and how it works, one thing is immediately apparent: a neural network often works with the recognition of the smallest information. The further this information is passed on in the network, the more details are put together.
This is different from our view of things! For example, we quickly recognise a car as a whole before we start looking at details such as shape, wheels, doors, etc.. The aspect of detail is important in this context, because the human brain certainly detects features like shape, wheels, doors etc. at lightning speed, and from this the identification ‘car’ is composed without us being aware of it. However, we see it initially without the details. This is easy to understand when you think of situations in which cars no longer look like cars, for example after an accident or if you see a car only in individual parts. Then our brain takes much longer to identify a car as such. In principle, moreover, we can identify a car as a car even if we have never seen exactly the particular model before.
By the way, in the AI this ability is called ‘generalisation’. So it describes the ability to recognise things without having been explicitly trained to do so. Imagine an AI is supposed to be used as a brake assistant. Technically you can't train it to recognise all the variants of trees lying on the road after a storm. And yet an AI can be trained in such a way that - with a high probability - the obstacle is recognised as a tree, and the brake is triggered. Amazing, isn't it?
But how do such wonderful pictures as those shown in the book by Arthur Miller come about?
The AI's way of working, processing small details first and then increasingly ‘seeing’ the big picture, is the key. If the AI were to work more humanly and deduce the details from the big picture, such pictures would initially look like the original and be robbed of their information layer by layer.
Here it is the other way round: the deeper the information which is taken out of the layers and made visible (which is without any doubt an outstanding achievement of the developer), the more the analysed image components are translated into a highly interesting picture. Important in this context: information of an image is often processed in parallel in different layers, or interpreted differently in different neurons – so that even duplications become visible[P2] . However, that also means that an AI that processes cat images will not produce images of houses or cars. It will always stay with the patterns that are processed. No more, but also no less.
From my point of view, therefore, AI is less the artist himself than a tool in the hands of an artist whose true genius is to make the visibility of numbers possible in a way never seen before.
References:
[i] See for example Gary Marcus, Adam Marblestone & Thomas Dean: ‘The atoms of neural computation’ in Science, 31 Oct 2014
All images used with kind permission from © 2020 Udo Wuertz